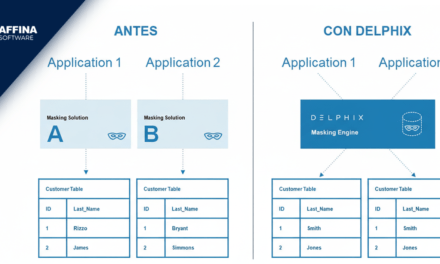
Cuando se habla de data pipelines, casi siempre se muestran diagramas limpios y flechas ordenadas. Fuente, transformación, destino. En teoría, todo fluye. Sin embargo, en entornos reales, un data pipeline no es una línea recta. Es una operación viva que se degrada, se ajusta, se rompe y se vuelve a armar.
Aquí es donde muchas organizaciones descubren algo incómodo: el problema no es la herramienta, sino no entender qué implica cada fase del pipeline cuando los datos ya están en producción, cuando hay usuarios esperando resultados y cuando un fallo impacta decisiones de negocio.
Un data pipeline no falla de golpe. Empieza a fallar en silencio, fase por fase.
Fase 1: Ingesta, cuando traer datos deja de ser trivial
Todo pipeline comienza trayendo datos. Al inicio suele ser simple: una base de datos, un archivo, una API. No obstante, conforme el negocio crece, también lo hacen las fuentes. Aparecen múltiples motores, formatos distintos, frecuencias irregulares y dependencias externas.
En este punto, la ingesta deja de ser solo “copiar datos”. Se convierte en un ejercicio de control. Control de tiempos, de volúmenes, de formatos y de consistencia. Cuando esta fase no se diseña bien, los errores se arrastran hacia adelante y se multiplican.
Además, si no existe visibilidad sobre qué datos entran y cuándo, los problemas aparecen tarde, cuando alguien pregunta por qué un reporte ya no cuadra.
Fase 2: Validación, la fase que muchos ignoran
Después de traer datos, debería venir una pregunta básica: ¿estos datos son confiables? Sin embargo, en muchos pipelines esta fase simplemente no existe. Los datos entran y se asume que “están bien”.
En entornos reales, eso rara vez es cierto. Valores nulos inesperados, duplicados, esquemas que cambian sin aviso o datos incompletos son el pan de cada día. Sin validación, el pipeline sigue avanzando, pero la calidad se degrada.
Aquí es donde los errores se vuelven costosos, porque ya no se detectan en el origen, sino cuando alguien consume el dato y pierde confianza en él.
Fase 3: Transformación, donde vive la lógica del negocio
La transformación es el corazón del pipeline. Es donde los datos se limpian, se combinan y se convierten en información útil. También es donde más decisiones se toman… y donde más riesgo se acumula.
Con el tiempo, las reglas crecen. Se agregan excepciones, cálculos, ajustes “temporales” que nunca se documentan. Sin una estructura clara, esta fase se vuelve opaca y difícil de mantener.
Además, cuando la transformación no está versionada ni controlada, nadie puede responder con certeza por qué un número cambió de un día a otro. El pipeline sigue funcionando, pero ya nadie confía del todo en él.
Fase 4: Orquestación, el orden que sostiene todo
En pipelines pequeños, la orquestación parece innecesaria. Todo corre en secuencia y listo. Pero en entornos reales, los procesos dependen unos de otros. Una carga fallida puede afectar a cinco procesos más.
La orquestación define qué corre, cuándo corre y qué pasa si algo falla. Sin ella, los pipelines se ejecutan a medias, se duplican procesos o se generan datos inconsistentes.
Aquí es donde muchas organizaciones descubren que no basta con mover datos. Hay que gobernar el flujo completo para que el pipeline sea predecible.
Fase 5: Persistencia, decidir dónde viven los datos
Una vez procesados, los datos deben almacenarse. Esta decisión no es menor. Data warehouse, data lake o combinaciones híbridas impactan directamente en rendimiento, costos y escalabilidad.
Cuando esta fase no se piensa bien, aparecen problemas de consultas lentas, costos inesperados o duplicación de información. El pipeline cumple su función, pero el entorno se vuelve difícil de sostener.
Persistir datos no es solo guardarlos. Es diseñar cómo se usarán a largo plazo.
Fase 6: Consumo, donde el pipeline se pone a prueba
El consumo es el momento de la verdad. Dashboards, modelos analíticos y aplicaciones dependen del pipeline para operar. Si los datos llegan tarde, incompletos o inconsistentes, el problema ya es visible.
Aquí suele aparecer la frase más peligrosa: “el dato antes sí estaba bien”. En realidad, el pipeline ya venía degradándose desde fases anteriores.
Un buen pipeline no solo entrega datos. Entrega confianza.
Fase 7: Monitoreo y gobierno, la fase olvidada
Finalmente, está la fase que sostiene a todas las demás. Monitoreo, trazabilidad, control de cambios y linaje de datos. Sin esto, el pipeline se convierte en una caja negra.
Cuando algo falla, nadie sabe dónde. Cuando un dato cambia, nadie sabe por qué. El pipeline sigue existiendo, pero deja de ser gobernable.
Esta fase no agrega datos nuevos, pero evita que todo lo demás se deteriore con el tiempo.
El data pipeline como producto, no como script
Visto así, un data pipeline no es un conjunto de scripts. Es un producto operativo que debe diseñarse, mantenerse y evolucionar. Cada fase tiene un propósito claro y un impacto directo en el negocio.
Las organizaciones que entienden esto dejan de construir pipelines frágiles y empiezan a crear plataformas de datos sostenibles. Las que no, terminan apagando incendios con cada nuevo requerimiento.
Conclusión
Las fases de un data pipeline no fallan por separado. Fallan en conjunto cuando no se entienden ni se gobiernan. Diseñar un pipeline real implica pensar más allá del movimiento de datos y asumir que cada fase tiene consecuencias operativas.
Un pipeline bien construido no solo mueve información. Sostiene decisiones, acelera equipos y mantiene la confianza en los datos a lo largo del tiempo.