
En muchos equipos de desarrollo y QA, los errores más costosos no aparecen por falta de pruebas, sino por pruebas hechas con datos incorrectos.
Ambientes que funcionan “en teoría”, pero que colapsan al llegar a producción. Casos que pasaron QA sin problemas y fallaron con usuarios reales. Reportes que no reflejan el comportamiento real del sistema.
En el fondo, el problema no siempre está en el código ni en la infraestructura. Está en los datos utilizados para probar.
El supuesto peligroso: “con datos ficticios es suficiente”
Durante años, la práctica común ha sido usar datos ficticios o incompletos para pruebas. Nombres genéricos, volúmenes pequeños y estructuras simplificadas.
Este enfoque parece seguro y rápido, pero introduce varios riesgos silenciosos:
- Las reglas de negocio no se comportan igual con datos reales.
- Los volúmenes pequeños no revelan problemas de rendimiento.
- Las relaciones entre tablas no se replican fielmente.
- Los casos extremos nunca se prueban.
El resultado es un entorno que no representa la realidad, aunque el código sea correcto.
Cuando las pruebas no reflejan producción
Las aplicaciones modernas operan sobre datos complejos: históricos largos, relaciones profundas, combinaciones poco frecuentes y comportamientos acumulativos.
Cuando los datos de prueba no reflejan esto:
- Los tiempos de respuesta cambian drásticamente en producción.
- Aparecen bloqueos que nunca se detectaron.
- Consultas aparentemente simples se vuelven costosas.
- Los flujos críticos fallan bajo carga real.
Las pruebas “pasaron”, pero el sistema no estaba preparado.
El dilema real: datos reales vs. datos seguros
Aquí aparece el conflicto clásico.
Los equipos necesitan datos reales para probar correctamente, pero las organizaciones no pueden exponer información sensible en entornos no productivos.
Copiar producción tal cual no es una opción viable cuando existen:
- Datos personales.
- Información financiera.
- Registros confidenciales.
- Requisitos de privacidad y cumplimiento.
Este dilema suele resolverse mal: o se sacrifican pruebas realistas, o se asume un riesgo innecesario.
Data Masking como solución práctica, no teórica
El enmascaramiento de datos no busca eliminar información, sino transformarla de forma segura sin perder su valor funcional.
Un enfoque correcto de Data Masking permite:
- Mantener formatos, longitudes y relaciones.
- Preservar la integridad referencial.
- Conservar distribuciones y patrones reales.
- Eliminar la exposición de datos sensibles.
Así, los equipos trabajan con datos que se comportan como producción, pero sin riesgos.
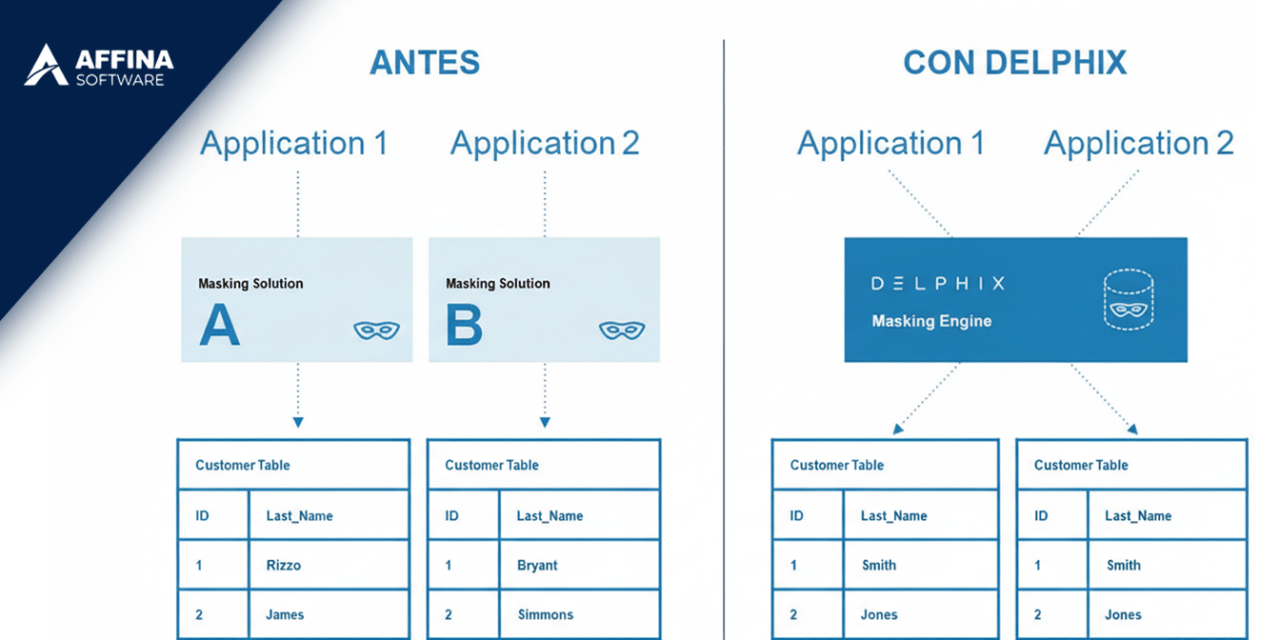
El producto en foco: Delphix Data Masking
Delphix Data Masking está diseñado para resolver este problema desde la raíz. No como una herramienta aislada, sino como parte del flujo de datos hacia entornos no productivos.
Su enfoque se basa en tres pilares:
Descubrimiento de datos sensibles
Identifica automáticamente información crítica dentro de las bases de datos. Esto evita depender de procesos manuales o supuestos incompletos.
Enmascaramiento con integridad
Aplica reglas de enmascaramiento que conservan relaciones entre tablas y coherencia funcional. Las pruebas siguen siendo realistas.
Automatización y consistencia
Los mismos datos se pueden entregar repetidamente, bajo las mismas reglas, reduciendo errores y reprocesos.
Impacto directo en la calidad de las pruebas
Cuando los equipos prueban con datos enmascarados pero realistas:
- Los defectos se detectan antes.
- Los escenarios extremos aparecen en QA.
- El rendimiento se evalúa con mayor precisión.
- Las validaciones reflejan el uso real del sistema.
Las pruebas dejan de ser un trámite y se convierten en una etapa confiable del ciclo de desarrollo.
Menos fricción entre seguridad y desarrollo
Uno de los beneficios más claros es organizacional.
Seguridad deja de ser un obstáculo para pruebas realistas. Desarrollo deja de improvisar datos. QA deja de validar escenarios irreales.
Cada área obtiene lo que necesita sin comprometer a las demás.
Conclusión
Las pruebas fallan cuando no se usan datos reales porque los sistemas no viven en un entorno simplificado. Viven en escenarios complejos, con volúmenes, relaciones y comportamientos que solo los datos reales pueden representar.
El Data Masking permite resolver este problema sin asumir riesgos innecesarios. Herramientas como Delphix Data Masking hacen posible trabajar con datos funcionales, seguros y repetibles en entornos no productivos.
Porque al final, no se trata solo de probar más.
Se trata de probar con la realidad correcta.



