
Las organizaciones que operan en entornos cloud como Azure enfrentan un dilema cada vez más evidente: necesitan proteger datos sensibles, pero al mismo tiempo no pueden frenar la velocidad a la que esos datos deben ser utilizados.
El enmascaramiento de datos surge como una respuesta natural a este reto. Sin embargo, en entornos modernos donde conviven analítica avanzada, inteligencia artificial y procesamiento distribuido, no basta con proteger la información. También es necesario hacerlo de forma eficiente, escalable y alineada con los tiempos del negocio.
El problema es que, en muchos casos, las estrategias tradicionales de data masking no están diseñadas para este contexto.
Y ahí es donde comienzan las fricciones.
¿Qué es el data masking en Azure?
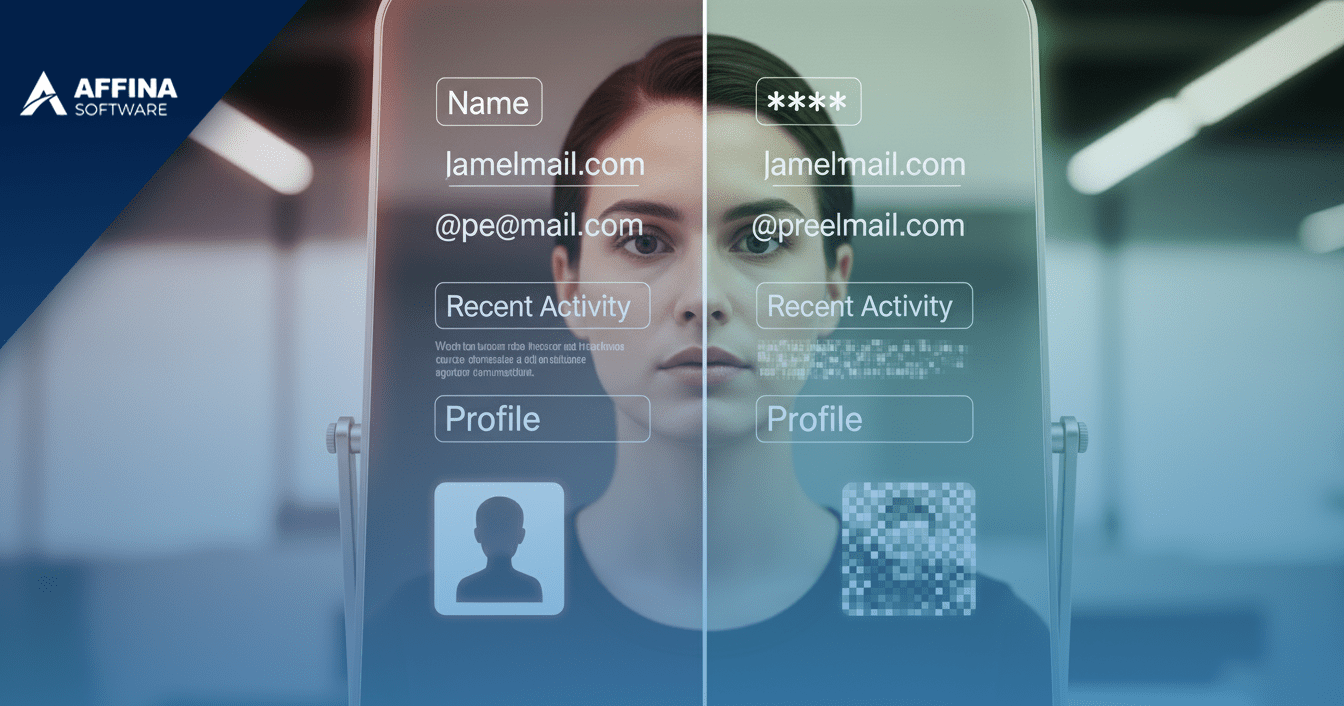
El data masking en Azure se refiere a la capacidad de proteger información sensible mediante su transformación, sin alterar el valor funcional del dato para análisis o uso operativo.
Azure incorpora mecanismos como el dynamic data masking, que permite ocultar información dependiendo del rol o nivel de acceso del usuario, sin modificar los datos originales almacenados.
Esto permite, por ejemplo, que un usuario con privilegios elevados visualice datos completos, mientras que otros usuarios solo accedan a versiones parcialmente ocultas.
Este enfoque es especialmente útil en entornos productivos donde se requiere trabajar con datos reales sin exponer información crítica en cada interacción.
Sin embargo, cuando el contexto cambia hacia analítica, pruebas o inteligencia artificial, este modelo empieza a mostrar limitaciones.
Por qué la velocidad importa en el data masking
En arquitecturas modernas, el tiempo que tarda un dato en estar disponible puede ser tan importante como su protección.
Procesos lentos de enmascaramiento generan retrasos en pipelines de analítica, entrenamiento de modelos y toma de decisiones.
Cuando los equipos dependen de datasets enmascarados para trabajar, cualquier demora en su disponibilidad impacta directamente en la capacidad de generar valor.
Esto se vuelve aún más crítico en entornos donde la analítica y la inteligencia artificial son parte central de la operación. Retrasar el acceso a datos significa retrasar insights, decisiones y, en muchos casos, ventajas competitivas.
En respuesta a esta presión, algunas organizaciones terminan tomando atajos, permitiendo el uso de datos sin enmascarar en ciertos entornos para no frenar el negocio.
El problema es evidente: se gana velocidad… pero se pierde control.
Retos del data masking en Azure
Aunque Azure ofrece capacidades nativas de enmascaramiento, su implementación en entornos empresariales presenta desafíos importantes.
Uno de los principales problemas es que el dynamic masking no altera los datos en su origen. Esto significa que, aunque el acceso esté controlado, la información sensible sigue existiendo en su forma original y puede ser expuesta en escenarios como exportaciones, respaldos o accesos indebidos.
A esto se suma la complejidad operativa. En entornos donde existen múltiples fuentes de datos, plataformas y roles de usuario, definir y mantener políticas de masking consistentes se vuelve una tarea difícil de escalar.
También existen limitaciones a nivel de integración. No todas las soluciones de masking se adaptan de forma natural a ecosistemas como Azure Data Factory, Data Lake o entornos híbridos, lo que introduce fricciones adicionales en los flujos de datos.
Otro reto relevante es la escalabilidad. Muchas soluciones tradicionales no están diseñadas para procesar volúmenes masivos de datos en entornos distribuidos, lo que genera cuellos de botella en pipelines críticos.
Finalmente, está el problema de la calidad del dato. Un enmascaramiento mal implementado puede distorsionar la información, afectando modelos analíticos y reduciendo el valor del dato en procesos de negocio.
Cómo acelerar el data masking en Azure
Superar estos retos requiere un cambio de enfoque. No se trata únicamente de aplicar masking, sino de integrarlo de forma inteligente dentro del flujo de datos.
Uno de los primeros pasos es adoptar static data masking, un enfoque que transforma los datos de manera irreversible desde su origen. A diferencia del masking dinámico, este método permite trabajar con datasets ya protegidos en cualquier entorno, eliminando riesgos asociados al acceso o exposición.
Otro elemento clave es la automatización del descubrimiento de datos sensibles. Identificar manualmente qué información debe protegerse no es viable en entornos de gran escala. Incorporar herramientas que detecten automáticamente datos sensibles permite acelerar el proceso y reducir errores.
También resulta fundamental integrar el masking directamente en los pipelines de datos. En lugar de tratarlo como un proceso independiente, se incorpora dentro del flujo, permitiendo que los datos se enmascaren mientras se mueven entre sistemas. Este enfoque reduce tiempos y evita reprocesos innecesarios.
A esto se suma el uso de plantillas y configuraciones predefinidas, que permiten estandarizar el enmascaramiento en entornos complejos, y la capacidad de escalar el procesamiento para soportar grandes volúmenes de datos sin degradar el rendimiento.
Finalmente, es indispensable mantener la calidad del dato. El objetivo no es solo proteger la información, sino garantizar que siga siendo útil para analítica, inteligencia artificial y toma de decisiones.
Beneficios de un enfoque moderno de data masking
Cuando el data masking se implementa correctamente dentro del ecosistema Azure, los beneficios van más allá del cumplimiento.
Las organizaciones pueden reducir significativamente los tiempos necesarios para preparar datos, pasando de procesos que tardan días o semanas a flujos que se ejecutan en cuestión de horas.
Esto impacta directamente en la capacidad de ejecutar proyectos de analítica, inteligencia artificial y machine learning sin retrasos operativos.
Además, se reduce el riesgo asociado a la exposición de datos sensibles, eliminando la necesidad de excepciones que comprometen la seguridad.
Otro beneficio clave es la escalabilidad. Un enfoque bien diseñado permite que el enmascaramiento crezca al mismo ritmo que los datos, sin convertirse en un cuello de botella.
Y, finalmente, se logra un equilibrio entre protección y utilidad, asegurando que los datos sigan siendo relevantes para el negocio.
Conclusión
El data masking en Azure ya no puede entenderse como un proceso aislado dentro de la seguridad de datos.
Se ha convertido en un componente crítico dentro de la arquitectura de datos moderna, donde la velocidad, la escalabilidad y el cumplimiento deben coexistir sin fricción.
Las organizaciones que continúan tratando el enmascaramiento como una tarea secundaria enfrentan un riesgo claro: frenar sus iniciativas de analítica o comprometer la seguridad de su información.
Por el contrario, aquellas que integran el masking de forma estratégica dentro de sus flujos de datos logran algo más valioso que el simple cumplimiento.